If you’ve ever wondered why your storage system seems to slow down or fill up faster than expected, the answer might lie in duplicate data. Understanding what is single instance storage can completely change how you think about managing data — whether you’re running a business, managing a server, or just trying to get smarter about IT infrastructure.
Last updated: June 9, 2026
What Is Single Instance Storage, Exactly?
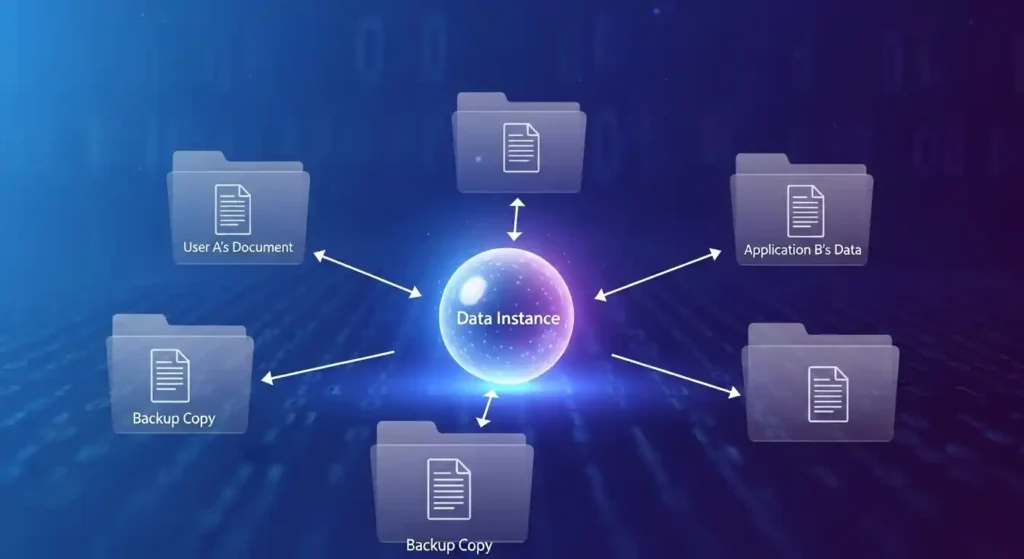
Single instance storage (SIS) is a data deduplication method that stores only one unique copy of a piece of data — no matter how many times it appears across a system. Instead of saving the same file over and over again, SIS keeps a single copy and uses references (or pointers) to link back to that one original.
Think of it like a library. Instead of every student buying the same textbook, the library keeps one copy and lets multiple students borrow it. Everyone gets access, but physical shelf space is used efficiently.
This approach is widely used in email servers, backup systems, file storage, and cloud infrastructure. It’s especially valuable in enterprise environments where thousands of users might store identical files — like company policy documents, software installers, or email attachments.
How Single Instance Storage Actually Works
Here’s where it gets interesting. When a new file arrives in a SIS-enabled system, the system runs a check. It asks: “Have I seen this exact piece of data before?”
This check typically happens through a hashing algorithm. Each file gets a unique fingerprint (called a hash). If the hash matches an existing file already stored, the system doesn’t save a second copy. Instead, it creates a pointer — a small reference that says “this file lives over there.”
If the hash is brand new, the file gets saved normally.
The whole process happens behind the scenes. End users don’t notice any difference. They open their files, access their emails, and everything works just as expected.
Hawaii 2: Everything You Need to Know Before You Go
The Role of Hash Functions
Hash functions are the engine behind SIS. Common algorithms like MD5 or SHA-256 generate a fixed-length string from the file’s contents. Even a tiny change in the file — a single character — creates a completely different hash. This ensures accuracy when identifying duplicates.
Pointers and References
Once a single instance is stored, every duplicate reference points back to it. These pointers are incredibly small in size, which is what makes SIS so storage-efficient. Instead of ten 5MB copies of a file taking up 50MB, you have one 5MB file and nine tiny pointers.
Where Single Instance Storage Is Commonly Used
SIS isn’t just a niche technology. It shows up in several familiar places:
- Email servers — Microsoft Exchange historically used SIS to avoid storing identical attachments multiple times across mailboxes.
- Backup and recovery systems — Backup tools use SIS to reduce redundant data across scheduled backups.
- Virtual machine environments — Multiple VMs often share identical OS files, making SIS extremely effective.
- Cloud storage platforms — Cloud providers use SIS (and broader deduplication techniques) to cut infrastructure costs.
- Enterprise file servers — Large organizations with shared drives benefit hugely from not storing the same onboarding document 500 times.
Single Instance Storage vs. Data Deduplication
People often use these terms interchangeably, but there’s a subtle difference worth knowing.
Single instance storage typically works at the file level — it identifies and eliminates duplicate files. Data deduplication, on the other hand, can work at the block or chunk level, breaking files into smaller pieces and finding duplicate segments even within different files.
So SIS is actually a specific type of deduplication — a foundational one that focuses on whole-file duplicates.
Pros and Cons of Single Instance Storage
Like any technology, SIS comes with real advantages and a few trade-offs.
Pros
- Saves significant storage space — In environments with lots of repeated data, space savings can reach 50–80%.
- Reduces storage costs — Less physical or cloud storage needed means lower hardware and subscription costs.
- Faster backups — With less data to process, backup windows shrink noticeably.
- Scalable for large environments — The bigger the organization, the more duplicate data typically exists, and the more SIS pays off.
- Transparent to end users — Users experience zero disruption. Files still open, move, and behave normally.
Cons
- Single point of failure risk — If the one stored instance becomes corrupted, every pointer referencing it breaks. That’s a serious vulnerability without proper redundancy.
- Performance overhead during indexing — The hashing and comparison process consumes CPU and memory resources, especially during large ingestion jobs.
- Less effective with unique data — If your data is already mostly unique (like raw video files or scientific datasets), SIS offers minimal benefit.
- Complexity in restore operations — Restoring data from SIS-enabled backups can require additional steps to resolve all pointer references correctly.
Common Mistakes to Avoid
Even when SIS is set up correctly, organizations tend to make a few recurring mistakes.
1. Skipping redundancy planning Since SIS stores only one copy of each unique file, losing that file means losing access for everyone pointing to it. Always pair SIS with solid backup and RAID configurations.
2. Applying SIS to the wrong data types Compressed files, encrypted data, and already-deduplicated archives don’t benefit from SIS. The system still does the hashing work but finds no savings. It’s wasted effort.
3. Ignoring performance monitoring The hashing process can put pressure on your system during peak hours. Teams often enable SIS and forget to monitor how it affects CPU and I/O performance over time.
4. Confusing SIS with full deduplication Assuming SIS handles block-level deduplication too can lead to inflated expectations. Know what your tool actually does — file-level vs. Block-level matters.
5. Not testing restore procedures Some teams test backups but never test restores from SIS-enabled systems. Pointer-based storage requires a working reference chain. If that chain breaks, recovery gets messy fast.
Best Practices for Single Instance Storage
Getting the most out of SIS means being intentional about how and where you deploy it.
- Audit your data first — Run a data analysis to identify where duplicates are most concentrated. Deploy SIS where the ROI is highest.
- Combine with tiered storage — Use SIS alongside hot/warm/cold storage tiers to maximize both space and access speed.
- Maintain multiple physical backups — Never rely on SIS alone for data protection. Store redundant copies in separate physical or geographic locations.
- Schedule indexing during off-peak hours — Let the system do its heavy lifting at night or on weekends when user activity is low.
- Regularly verify data integrity — Run integrity checks on stored instances to catch corruption early before it affects all referencing pointers.
- Document your SIS configuration — If something goes wrong, your team needs to understand the storage architecture quickly. Clear documentation saves hours during incidents.
A Quick Real-World Example
Imagine a law firm with 200 employees. Every Monday, the HR team sends out a 10MB policy update PDF to the entire staff. Without SIS, the email server stores 200 separate 10MB files — that’s 2GB just for one weekly email.
With SIS enabled, the server stores the PDF once (10MB) and creates 199 tiny pointers. Space used: roughly 10MB instead of 2GB. Over a year, that single use case alone saves hundreds of gigabytes.
Multiply that across contracts, legal templates, court filings, and software tools — and the savings become enormous.
Conclusion
Single instance storage is one of those behind-the-scenes technologies that quietly does a lot of heavy lifting. It’s not glamorous, but it’s genuinely powerful. By storing one unique copy of data and using pointers for the rest, organizations can dramatically cut storage consumption, reduce costs, and simplify their infrastructure.
That said, it’s not a set-it-and-forget-it solution. You need proper redundancy, smart deployment choices, and ongoing monitoring to get the full benefit without the risk.
If your organization deals with large volumes of repeated data — emails, documents, system images, or backups — SIS is absolutely worth evaluating. Start with a data audit, identify your high-duplication zones, and go from there.
Frequently Asked Questions
1. What is single instance storage used for?
It’s used to eliminate duplicate copies of files in storage systems, saving space and reducing costs. Common use cases include email servers, backup systems, and cloud storage platforms.
2. Is single instance storage the same as deduplication?
Not exactly. SIS is a type of deduplication that works at the file level. Broader deduplication techniques also work at the block or chunk level, catching duplicates within files.
3. Does single instance storage affect file access speed?
For end users, file access typically feels the same. However, during heavy indexing or large ingestion jobs, there can be some CPU and I/O overhead on the system itself.
4. What happens if the single stored instance gets corrupted?
Every pointer referencing that file loses access to valid data. This is why SIS must always be paired with strong redundancy and backup strategies to avoid catastrophic data loss.
5. Which industries benefit most from single instance storage?
Industries with high volumes of repeated documents — legal, healthcare, finance, education, and large enterprises — see the greatest storage savings and efficiency gains from SIS.
Source: Wired
Related Articles
- Comedian Kevin Hart Height: The Truth About the Short King
- Cloud Security Tips to Protect Your Business in 2026
- VIPBox Sports: Your Ultimate Online Streaming Destination
Editorial Note: This article was researched and written by the Floral Loft SAC editorial team. We fact-check our content and update it regularly. For questions or corrections, contact us. For readers asking “What is single instance storage”, the answer comes down to the specific factors covered above.




