You are staring at your monitoring dashboard at 2:00 AM, watching the latency spikes climb. Your current database is choking under the weight of concurrent requests, and no amount of vertical scaling seems to fix the bottleneck. You’ve tried indexing everything, refactoring your joins, and adding caching layers, but the fundamental structure just isn’t holding up. You need a solution that handles high-throughput writes without sacrificing the consistency your application demands. You feel like you’re fighting your tools instead of building your product, and you need a way out.
The sruffer db framework was designed for exactly this moment. It bridges the gap between the rigid structure of traditional relational systems and the chaotic speed of NoSQL. In this guide, we will dive deep into how you can implement and optimize this technology to ensure your backend never becomes the weak link in your stack again.
What is Sruffer DB and Why Does It Matter?
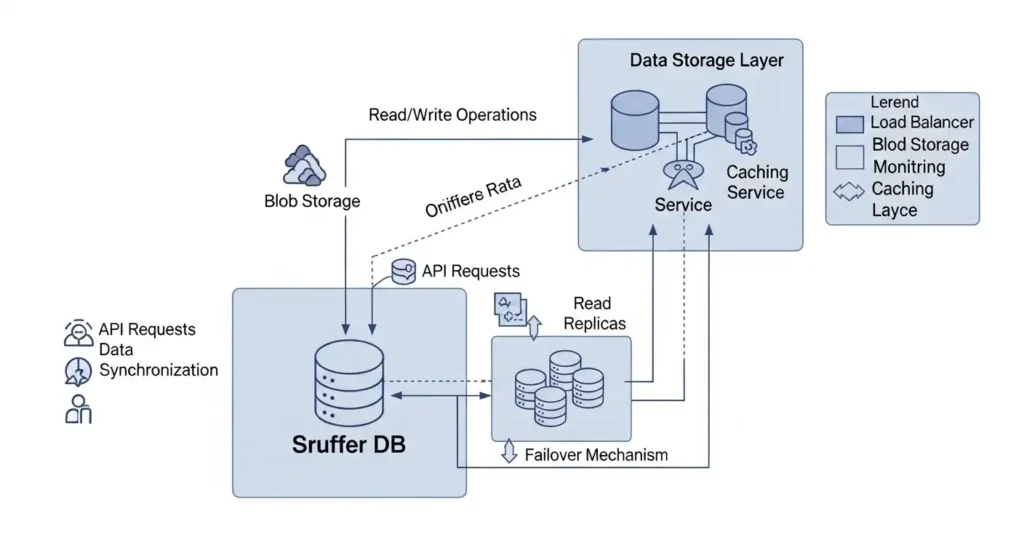
At its core, sruffer db is a high-performance, distributed database engine optimized for specific heavy-load workloads where traditional ACID compliance meets the need for horizontal scalability. Unlike standard databases that struggle when data exceeds a single server’s memory, this system uses a “sharding-first” philosophy.
It organizes data into localized clusters that communicate through a high-speed peering protocol. This means when you query the system, it doesn’t have to scan a massive, monolithic table. Instead, it directs the request to the specific node where that data lives. For developers, this translates to predictable latency, regardless of whether you have ten thousand rows or ten billion.
Sruffer DB Explained with a Real-World Scenario
Think about a global ride-sharing application. Every second, thousands of drivers are updating their GPS coordinates, while thousands of riders are searching for nearby cars. If you put all this data into a single traditional table, the write-locks alone would crash the system during rush hour.
In a sruffer db environment, the data is partitioned by “Cell Clusters.” The coordinates for drivers in New York live on one set of nodes, while London stays on another. When a rider in Brooklyn opens the app, the database doesn’t even look at the London data.
This localized execution ensures that a surge in traffic in one city doesn’t slow down the experience for users on the other side of the world. It provides the “Isolation of Workload” that modern, globalized apps require to maintain a 99.99% uptime.
Business Vertical Classification Categories: The Ultimate Guide to Market Focus
How to Implement Sruffer DB: Step-by-Step Instructions
Transitioning to this architecture requires a shift in how you think about data relationships. Follow these steps to set up your first high-performance cluster.
-
Define Your Partition Key: This is the most critical step. You must choose a key that distributes data evenly. Avoid using timestamps as your primary partition key, as this creates “hot spots” where all new data hits a single node.
-
Initialize the Node Cluster: Use the command-line interface (CLI) to spin up your seed nodes. Ensure you have at least three nodes for a development environment to test the consensus protocol.
-
Configure Replication Factors: Decide how many copies of your data should exist. For production, a factor of 3 is standard. This ensures that if one node fails, your application remains online without data loss.
-
Schema Mapping: Map your existing JSON or relational objects to the internal schema. Use the “Strict Typing” mode during migration to catch data inconsistencies early.
-
Establish Connection Pooling: Configure your application backend (Node.js, Python, or Go) to use a persistent connection pool. This avoids the overhead of creating a new handshake for every single query.
-
Monitor the Rebalance: As you load data, watch the rebalancing logs. The system should automatically move data chunks to ensure no single node exceeds 70% disk utilization.
Common Mistakes People Make
The most frequent error is treating sruffer db like a traditional SQL database. Many developers try to perform massive, multi-join queries across different shards. While the system allows for this, it’s computationally expensive because it requires the database to pull data from multiple physical servers into a temporary buffer.
Another mistake is ignoring the compaction strategy. As data is updated and deleted, “tombstones” (markers for deleted data) can accumulate. If you don’t configure your background compaction properly, read performance will degrade over time as the system has to skip over millions of deleted entries to find a single active record.
Finally, people often under-provision the network bandwidth. Because nodes are constantly “gossiping” to keep data synchronized, the internal network traffic can be significant. If you are running this in a cloud environment like AWS or Azure, ensure your instances have enhanced networking enabled.
Sruffer DB vs. Traditional Relational Databases
To understand where this technology fits, look at how it compares to the standard SQL databases you might be used to.
| Feature | Sruffer DB | Traditional SQL (Postgres/MySQL) |
| Scaling | Horizontal (add more cheap servers) | Vertical (buy a bigger, expensive server) |
| Data Model | Multi-model (Document + Key-Value) | Strictly Relational (Tables/Rows) |
| Consistency | Tunable (Strong to Eventual) | Strict ACID Compliance |
| Join Operations | Optimized for Localized Joins | Global Joins across all data |
| Write Speed | Extremely High (Append-only logs) | Moderate (B-Tree updates) |
Pro Tips for Database Excellence
To get the most out of your sruffer db implementation, you should use Materialized Views. Instead of calculating complex aggregations (like “total sales per region”) every time a user loads a dashboard, let the database maintain a pre-calculated view that updates incrementally as new data arrives.
Another “pro” move is to use Compression Dictionaries. Since much of the data in a large database is repetitive, enabling dictionary-based compression can often reduce your storage footprint by 40% to 60%. This doesn’t just save money on disk space; it actually speeds up reads because less data needs to be moved from the disk into the CPU cache.
Lastly, always implement Client-Side Load Balancing. Don’t just point your app at one node. Use a driver that’s “cluster-aware,” so the application knows which node holds the specific data it needs and connects to it directly, skipping an extra hop.
Frequently Asked Questions
Can I run sruffer db on-premises?
Yes, it’s platform-agnostic. While it performs exceptionally well in containerized environments like Kubernetes, it can be installed directly on bare-metal Linux servers for maximum performance.
Is sruffer db suitable for small projects?
If your data fits comfortably on a single server and you don’t expect rapid growth, a simpler relational database might be easier to manage. This tool shines when you anticipate crossing the “multi-terabyte” threshold.
How does it handle security?
It supports end-to-end encryption for data at rest and in transit. It also integrates with standard identity providers using OIDC and LDAP for role-based access control.
Does it support full-text search?
Yes, it has a built-in secondary indexing engine that allows for high-speed text searching without needing an external tool like Elasticsearch for basic use cases.
What happens during a network partition?
You can configure the system’s behavior based on the CAP theorem. You can choose to prioritize “Availability” (letting users read/write even if nodes are disconnected) or “Consistency” (blocking writes until the network is restored).
Taking the Next Step with Sruffer DB
Mastering sruffer db is about more than just learning a new syntax; it’s about building a foundation that allows your application to grow without limits. You now understand that the secret to high-speed data isn’t just about raw power—it’s about smart distribution and localized execution.
If you are tired of fighting slow queries and deadlocked tables, your next move is clear. Start by auditing your current data access patterns to identify which tables would benefit most from a sharded architecture. Once you identify your “hot” data, begin a pilot migration of that specific module. You will likely find that by offloading your heaviest workloads to a specialized engine, the rest of your stack will breathe a sigh of relief.
Source: Wired
Related Articles
- Nikane Madeira: Discover the Island Experience Everyone Is
- Kadazza: The Ultimate Guide to This Innovative Platform
- Rolex Express: The Fast Track to Luxury, Precision, and
Editorial Note: This article was researched and written by the Floral Loft SAC editorial team. We fact-check our content and update it regularly. For questions or corrections, contact us.




